An Introduction to tseffects: Dynamic Inferences from Time Series (with Interactions)
Soren Jordan, Garrett N. Vande Kamp, and Reshi Rajan
2026-02-05
Source:vignettes/tseffects-vignette.Rmd
tseffects-vignette.RmdAutoregressive distributed lag (A[R]DL) models (and their reparameterized equivalent, the Generalized Error-Correction Model [GECM]) are the workhorse models in uncovering dynamic inferences. Since the introduction of the general-to-specific modeling strategy of Hendry (1995), users have become accustomed to specifying a single-equation model with (possibly) lags of the dependent variable included alongside the independent variables (in differences or levels, as appropriate) to capture dynamic inferences. Through all of the follolwing, we assume users are familiar with such models and their best practices, including testing for stationarity on both sides of the equation (Philips 2022), equation balance (Pickup and Kellstedt 2023), the absence of serial autocorrelation in the residuals, or testing for moving averages (Vande Kamp and Jordan 2025). ADL models are simple to estimate; this is what makes them attractive. Once these models are estimated, what is less clear is how to uncover a rich set of dynamic inferences from these models. This complication arises in three key areas.
First: despite robust work on possible quantities of interest that can be derived from dynamic models (see De Boef and Keele (2008)), the actual calculation of these quantities (and corresponding measures of uncertainty) remains a considerable difficulty for practitioners. Formulae are often complex and model-dependent (i.e. on the underlying lag structure of the model), especially when considering periods other than an instantaneous effect or a long-run multiplier. While other, simulation-based methods exist to interpret A[R]DL models (as in Jordan and Philips Jordan and Philips (2018a)), these methods are not well equipped to test hypotheses of interest.
Second: methodological approaches to unbalanced equations or integrated series routinely involve differencing one or both sides of the ADL model to ensure stationarity. Yet researchers might wish to uncover inferences about their variables in levels, even if they are modeled in differences. Some work approaches this by generalizing shock histories to allow for inferences in levels or differences (Vande Kamp, Jordan, and Rajan (2025)), no implementation of this approach exists in software.
Third: the problem grows much more complicated when considering conditional dynamic relationships. Though recent work advances a unified modeling strategy through a general framework, including cross-lags (see Warner, Vande Kamp, and Jordan (2026)), no similar general approach exists to visualize interactive effects. This problem is complicated by the observation that, in any dynamic interactive model, time itself is a moderator that must be accounted for (Vande Kamp, Jordan, and Rajan (2022)) in addition to the values of both variables in the interaction (well established since Brambor, Clark, and Golder (BramborClarkGolder2006?)).
tseffects solves these problems. Our point of departure
is leveraging Box, Jenkins, and Reinsel (1994). Rather than deriving period-specific and
cumulative effects for every combination of independent variables, lags,
and lags of the dependent variable (as in Wilkins (2018), for instance), or simulating the
unfolding effects over time (as in Jordan and Philips (2018b)), Box, Jenkins, and Reinsel provide
simple formulae that focus on the unique period-specific contribution of
a change in an independent variable. To show how, we first re-introduce
the ADL and GECM models and define typical effects calculated from these
models. We then apply those effects to each of the unique problems
outlined above.
The ADL/GECM model
To help ensure consistency in notation, we define the ADL(,) model as follows
Similarly, we define its GECM equivalent as
Notice in particular the form of the GECM with a single first lag of
both the dependent and independent variable in levels. (The GECM
calculations provided by GDRF.gecm.plot assume this
correctly specified GECM and use the variable translations between the
GECM and ADL to define the coefficient in ADL terms. These translations
are done by gecm.to.adl.) The model might contain other
regressors, but, for unconditional dynamic models, these regressors are
unimportant for understanding the dynamic effects of variable
.
We will use these models to define and recover time-series quantities of
interest from the underlying model.
A unified approach to inferences: the Generalized Dynamic Response Function
The ADL model is well established, and traditoinal quantities of interest are well known. Box, Jenkins, and Reinsel (1994) define quantities of interest that result from various shock histories applied to an independent variable. The first is the impulse response function (IRF) (or perhaps a short-run effect).
We additionally define the step response function (SRF), also referred to as a cumulative impulse response function in the time series literature.
These quantities are often estimated from an ADL including a dependent variable in levels or differences, an independent variable in levels or differences, or a mix of both. Yet scholars might want to make inferences regarding the dependent variable in levels regardless of its order of differencing in the ADL model. Or, scholars might want to uncover the effects of a shock history applied to an independent variable in levels, even if that independent variable is entered into the ADL in differences. Regular ADL formulae cannot deliver on this expectation. To resolve this deficiency, Vande Kamp, Jordan, and Rajan (2025) introduce the General Dynamic Response Function (GDRF)
with the following elements:
- : the number of times the independent variable is differenced before determining the effect of the shock on the dependent variable
- : the number of times the independent variable is differenced before a shock is applied to it
- : the number of time periods since a shock was applied
deserves special explanation. (Vande Kamp, Jordan, and Rajan 2025) demonstrate how the binomial function can be used to represent traditional and beyond-traditional shock histories typically examined in time series
- : Shock sequence ; Linear Trend Coefficient of
- : Shock sequence ; Permanent One-Unit Increase (Step)
- : Shock sequence One-Time, One-Unit Increase (Pulse)
The second virtue of the binomial coefficient is that it translates between variables in levels and in differences. (Vande Kamp, Jordan, and Rajan 2025) prove that an arbitrary shock history for a variable in levels is equivalent to another counterfactual shock history to that same variable after differencing, simply adjusting the parameter :
$${s,h, d.y, 0} & E[{d.y}Y_{t+s}({d.x}(x_{1:t-1}), ^{d.x}(x_{t:T} + c_{0:T-t, h})) - {d.y}Y_{t+s}({d.x}(x_{1:T}))] = {s,h-d.x, d.y, d.x}\
So the GDRF “translates” these popular shock histories to recover
inferences in the desired form of the independent and dependent
variables, regardless of their modeled level of differencing, given the
specified shock history. All scholars need to do is estimate the ADL
model and choose a shock. The virtue of tseffects is that
it automatically does this translation for you.
Computationally, the benefit of tseffects is that it
applies these formulae symbolically. Rather than performing many
recursive calculations as effects extend into future time periods, a
symbolic representation of those formulae are built (using
mpoly: (Kahle 2013)) that
only need to be evaluated once. We can also peek “under the hood” at
these formulae, perhaps as a teaching aid, to observe the GDRF in
different periods, based on the model specified.
Two subfunctions: pulse.calculator and
general.calculator
While its unlikely that users will want to interact with these
functions, they might be useful either for teaching or for developing a
better understanding of the GDRF. Despite their names, neither function
actually does any “calculation”; rather, they return an
mpoly class of the formula that would be evaluated.
The first is pulse.calculator. Like its name implies,
this calculates the traditional pulse effect for time period
up to $s = $ some limit. It returns a list of formulae,
each one the pulse effect for the relevant period. (Time series scholars
might refer to these as the period-specific effects.) It constructs
these formulae given a named vector of the relevant
variables (passed to x.vrbl) and their corresponding lag
orders, as well as the same for
(passed to y.vrbl), if given. Though most ADLs include a
lagged dependent variable to allow for flexible dynamics, it is entirely
possibly that a finite dynamic model is more appropriate: in this case,
y.vrbl would be NULL.
Imagine a simple finite dynamic model, where the
variables are mood, l1.mood, and
l2.mood (lags need not be consecutive, though in a
well-specified ADL they likely are). pulse.calculator would
look like
library(tseffects)
ADL.finite <- pulse.calculator(x.vrbl = c("mood" = 0, "l1_mood" = 1, "l2_mood" = 2),
y.vrbl = NULL,
limit = 5)This list is six elements long: including the pulses for each period
from 0 to 5. These will naturally be more complex if there are more
sophisticated dynamics through a lagged dependent variable. For
instance, if you estimate an ADL(1,2), where the
variables are mood, l1.mood, and
l2.mood and the dependent variable is policy
(with its first lag l1.policy).
ADL1.2.pulses <- pulse.calculator(x.vrbl = c("mood" = 0, "l1_mood" = 1, "l2_mood" = 2),
y.vrbl = c("l1_policy" = 1),
limit = 5)These pulses form the basis of the GDRF, given the order of
differencing of
and
and the specified shock history
.
To create the formulae for the GDRF, general.calculator
requires five arguments, most of which are defined above:
d.x and d.y (defined with respect to the
GDRF), h (the shock history applied), limit,
and pulses. The novel argument, pulses, is the
list of pulses for each period in which a GDRF is desired.
Assume the same ADL(1,2) from above. To recover the formulae for a
GDRF of a pulse shock, assuming that both mood and
policy are in levels (such that both d.x and
d.y are 0), we would run
general.calculator(d.x = 0, d.y = 0, h = -1, limit = 5, pulses = ADL1.2.pulses)
#> $formulae
#> $formulae[[1]]
#> [1] "mood "
#>
#> $formulae[[2]]
#> [1] "l1_mood + l1_policy * mood "
#>
#> $formulae[[3]]
#> [1] "l2_mood + l1_policy * l1_mood + l1_policy**2 * mood "
#>
#> $formulae[[4]]
#> [1] "l1_policy * l2_mood + l1_policy**2 * l1_mood + l1_policy**3 * mood "
#>
#> $formulae[[5]]
#> [1] "l1_policy**2 * l2_mood + l1_policy**3 * l1_mood + l1_policy**4 * mood "
#>
#> $formulae[[6]]
#> [1] "l1_policy**3 * l2_mood + l1_policy**4 * l1_mood + l1_policy**5 * mood "
#>
#>
#> $binomials
#> $binomials[[1]]
#> [1] 1
#>
#> $binomials[[2]]
#> [1] 1 0
#>
#> $binomials[[3]]
#> [1] 1 0 0
#>
#> $binomials[[4]]
#> [1] 1 0 0 0
#>
#> $binomials[[5]]
#> [1] 1 0 0 0 0
#>
#> $binomials[[6]]
#> [1] 1 0 0 0 0 0(Since general.calculator is “under the hood,”
h can only be specified as an integer. Later, in a more
user-friendly function, we will see that shock histories can also be
specified using characters.)
Recall that we might want to generalize our inferences beyond simple
ADLs with both variables in levels. For exposition, assume that
mood was integrated, so, to balance the ADL, it needed to
be entered in differences. The user does this and enters
variables as d_mood, l1_d_mood, and
l2_d_mood. pulse.calculator would look
like
ADL1.2.d.pulses <- pulse.calculator(x.vrbl = c("d_mood" = 0, "l1_d_mood" = 1, "l2_d_mood" = 2),
y.vrbl = c("l1_policy" = 1),
limit = 5)These pulses look identical to the ones from
ADL1.2.pulses. But tseffects allows the user
to recover inferences of a shock history applied to
in levels, rather than its observed form of differences. All we need to
do is specify the d.x order.
general.calculator(d.x = 1, d.y = 0, h = -1, limit = 5, pulses = ADL1.2.d.pulses)
#> $formulae
#> $formulae[[1]]
#> [1] "d_mood "
#>
#> $formulae[[2]]
#> [1] "l1_d_mood + l1_policy * d_mood - d_mood "
#>
#> $formulae[[3]]
#> [1] "l2_d_mood + l1_policy * l1_d_mood + l1_policy**2 * d_mood - l1_d_mood - l1_policy * d_mood "
#>
#> $formulae[[4]]
#> [1] "l1_policy * l2_d_mood + l1_policy**2 * l1_d_mood + l1_policy**3 * d_mood - l2_d_mood - l1_policy * l1_d_mood - l1_policy**2 * d_mood "
#>
#> $formulae[[5]]
#> [1] "l1_policy**2 * l2_d_mood + l1_policy**3 * l1_d_mood + l1_policy**4 * d_mood - l1_policy * l2_d_mood - l1_policy**2 * l1_d_mood - l1_policy**3 * d_mood "
#>
#> $formulae[[6]]
#> [1] "l1_policy**3 * l2_d_mood + l1_policy**4 * l1_d_mood + l1_policy**5 * d_mood - l1_policy**2 * l2_d_mood - l1_policy**3 * l1_d_mood - l1_policy**4 * d_mood "
#>
#>
#> $binomials
#> $binomials[[1]]
#> [1] 1
#>
#> $binomials[[2]]
#> [1] 1 -1
#>
#> $binomials[[3]]
#> [1] 1 -1 0
#>
#> $binomials[[4]]
#> [1] 1 -1 0 0
#>
#> $binomials[[5]]
#> [1] 1 -1 0 0 0
#>
#> $binomials[[6]]
#> [1] 1 -1 0 0 0 0As (Vande Kamp, Jordan, and Rajan 2025) suggest, scholars should be very thoughtful about the shock history applied. These shocks are applied to the underlying independent variable in levels. Since is integrated in this example, it might be more reasonable to imagine that the underlying levels variable is actually trending. To revise this expectation and apply a new shock history, we would run
general.calculator(d.x = 1, d.y = 0, h = 1, limit = 5, pulses = ADL1.2.d.pulses)
#> $formulae
#> $formulae[[1]]
#> [1] "d_mood "
#>
#> $formulae[[2]]
#> [1] "l1_d_mood + l1_policy * d_mood + d_mood "
#>
#> $formulae[[3]]
#> [1] "l2_d_mood + l1_policy * l1_d_mood + l1_policy**2 * d_mood + l1_d_mood + l1_policy * d_mood + d_mood "
#>
#> $formulae[[4]]
#> [1] "l1_policy * l2_d_mood + l1_policy**2 * l1_d_mood + l1_policy**3 * d_mood + l2_d_mood + l1_policy * l1_d_mood + l1_policy**2 * d_mood + l1_d_mood + l1_policy * d_mood + d_mood "
#>
#> $formulae[[5]]
#> [1] "l1_policy**2 * l2_d_mood + l1_policy**3 * l1_d_mood + l1_policy**4 * d_mood + l1_policy * l2_d_mood + l1_policy**2 * l1_d_mood + l1_policy**3 * d_mood + l2_d_mood + l1_policy * l1_d_mood + l1_policy**2 * d_mood + l1_d_mood + l1_policy * d_mood + d_mood "
#>
#> $formulae[[6]]
#> [1] "l1_policy**3 * l2_d_mood + l1_policy**4 * l1_d_mood + l1_policy**5 * d_mood + l1_policy**2 * l2_d_mood + l1_policy**3 * l1_d_mood + l1_policy**4 * d_mood + l1_policy * l2_d_mood + l1_policy**2 * l1_d_mood + l1_policy**3 * d_mood + l2_d_mood + l1_policy * l1_d_mood + l1_policy**2 * d_mood + l1_d_mood + l1_policy * d_mood + d_mood "
#>
#>
#> $binomials
#> $binomials[[1]]
#> [1] 1
#>
#> $binomials[[2]]
#> [1] 1 1
#>
#> $binomials[[3]]
#> [1] 1 1 1
#>
#> $binomials[[4]]
#> [1] 1 1 1 1
#>
#> $binomials[[5]]
#> [1] 1 1 1 1 1
#>
#> $binomials[[6]]
#> [1] 1 1 1 1 1 1(Notice that the pulses do not change.) Recall that these are “under the hood”: we expect instead that most users will interact with the full calculation and plotting functions, discussed below.
User-friendly effects: GDRF.adl.plot and
GDRF.gecm.plot
Again, we expect most users will not interact with these calculators.
Instead, they will estimate an ADL model via lm and expect
easy-to-use effects. To achieve this directly, we introduce
GDRF.adl.plot. We gloss over arguments that we’ve already
seen in pulse.calculator and
general.calculator:
-
x.vrbl: a named vector of the variable and its lag orders -
y.vrbl: a named vector of the variable and its lag orders (if a lagged dependent variable is in the model) -
d.x: the order of differencing of the independent variable before a shock is applied -
d.y: the order of differencing of the dependent variable before effects are recovered -
s.limit: the number of periods for which to calculate the effects of the shock (the default is 20)
Now, since effects will be calculated, users must also provide a
model: the lm object containing the
(well-specified, balanced, free of serial autocorrelation, etc. ADL
model) that has the estimates. Users must also specify a shock history
through shock.history. Users can continue to specify an
integer that represents n (from above) or can use the
phrases pulse (for
)
and step (for
).
Users have already indicated the order of differencing of
and
(through d.x and d.y): now
general.calculator can leverage this information and the
supplied shock.history to deliver inferences about
in either levels or differences through inferences.y and
inferences.x. If both
and
are entered into the ADL in levels (so that d.x and
d.y are 0), inferences.y and
inferences.x default to levels. If, however,
either
or
(or both) are entered in differences, users can recover causal effects
from a shock history applied to
in levels, or to a dependent variable realized in levels. However,
they don’t have to. The shock can still be applied to
in differences, or the effects can be realized on
in differences: just change inferences.x to
differences (for the former) or inferences.y
to differences (for the latter).
A few options allow users to tailor levels and types of uncertainty
desired. The first is the type of standard errors calculated from the
model: users can specify any type of standard error accepted by
vcovHC in the sandwich package: this is done
by se.type = (where const is the default).
Users can also specify a level of uncertainty to the delta method other
than 0.95; this is done through dM.level.
Three final arguments control the output returned to the user.
-
return.plot: we assume most users would like a visualization of these results and nothing else (default isTRUE) -
return.data: if the user wants the raw data (to design their ownggplot, for instance), this argument should beTRUE(default isFALSE) -
return.formulae: the formulae can be very complex, but perhaps users want to see the particular formula for the effect in some particular period . Ifreturn.formulae = TRUE, these are returned as a list, along with the binomial series that represents the shock history (default isFALSE)
We’ll use the toy time series data included with the package to illustrate the function. These data are purely expository, as is the model. We do not advocate for this model.
data(toy.ts.interaction.data)
# Fit an ADL(1, 1)
model.adl <- lm(y ~ l_1_y + x + l_1_x, data = toy.ts.interaction.data)
test.pulse <- GDRF.adl.plot(model = model.adl,
x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
d.x = 0,
d.y = 0,
shock.history = "pulse",
inferences.y = "levels",
inferences.x = "levels",
s.limit = 20,
return.plot = TRUE,
return.formulae = TRUE)
This recovers the pulse effect. We can also observe the formulae and
associated binomials in test.pulse$formulae and
test.pulse$binomials. test.pulse$plot contains
the plot: the effect of applying a pulse shock to
.
If we wanted the step effect, we would change
shock.history.
test.pulse2 <- GDRF.adl.plot(model = model.adl,
x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
d.x = 0,
d.y = 0,
shock.history = "step",
inferences.y = "levels",
inferences.x = "levels",
s.limit = 20,
return.plot = TRUE,
return.formulae = TRUE)
Equivalently, we could specify shock.history =
0 (since this is the value of
that represents a step shock history).
Imagine that the variable was actually integrated, so, for balance, it was entered into the model in differences.
data(toy.ts.interaction.data)
# Fit an ADL(1, 1)
model.adl.diffs <- lm(y ~ l_1_y + d_x + l_1_d_x, data = toy.ts.interaction.data)To observe the causal effects of a pulse shock history applied to in levels, we would run
GDRF.adl.plot(model = model.adl.diffs,
x.vrbl = c("d_x" = 0, "l_1_d_x" = 1),
y.vrbl = c("l_1_y" = 1),
d.x = 1,
d.y = 0,
shock.history = "pulse",
inferences.y = "levels",
inferences.x = "levels",
s.limit = 20,
return.plot = TRUE)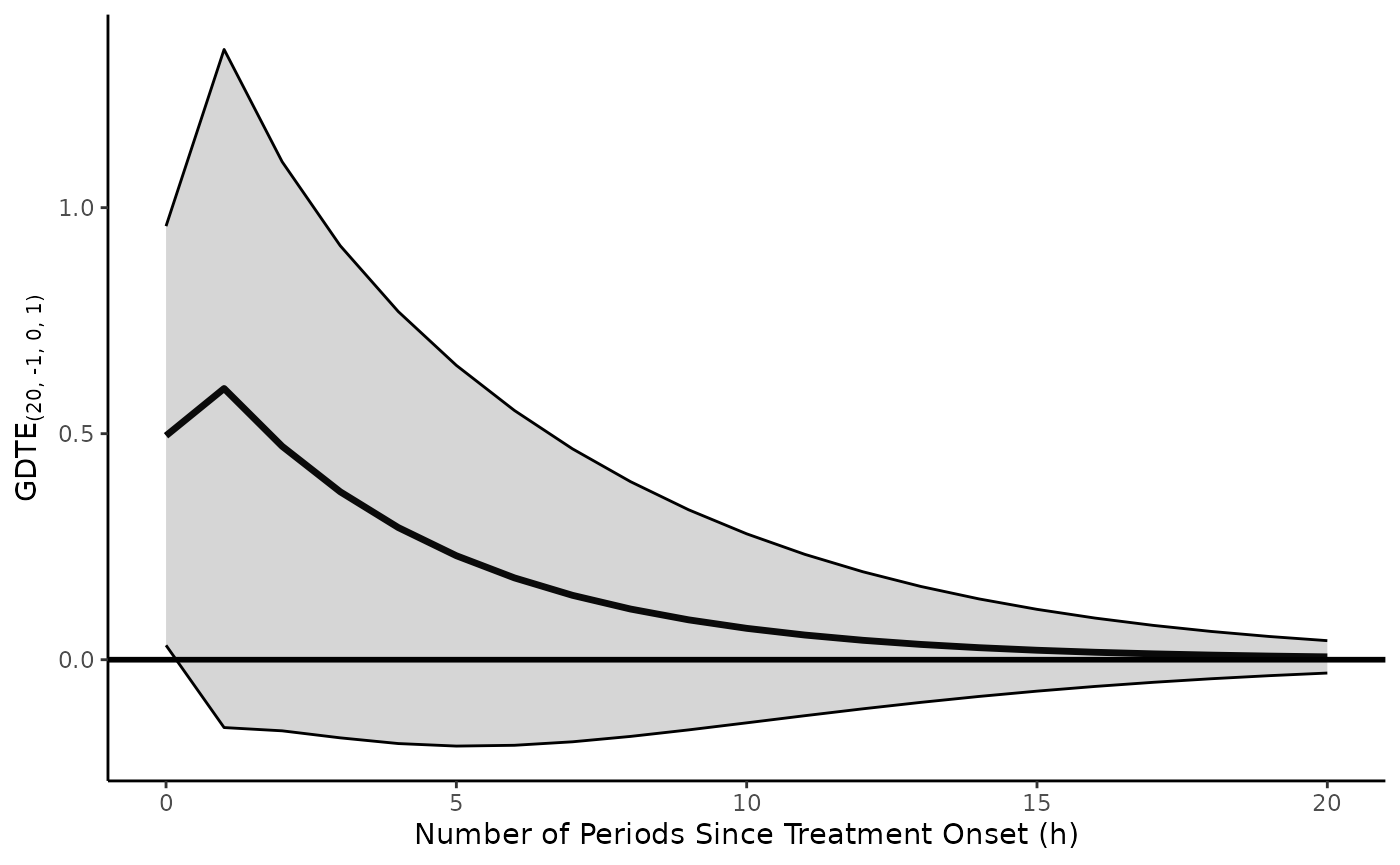
(Notice the change in d.x and the x.vrbl).
Suppose, though, that we wanted to apply this pulse to
in differences. We just change the form of
inferences.x, leaving all other arguments the same.
GDRF.adl.plot(model = model.adl.diffs,
x.vrbl = c("d_x" = 0, "l_1_d_x" = 1),
y.vrbl = c("l_1_y" = 1),
d.x = 1,
d.y = 0,
shock.history = "pulse",
inferences.y = "levels",
inferences.x = "differences",
s.limit = 20,
return.plot = TRUE)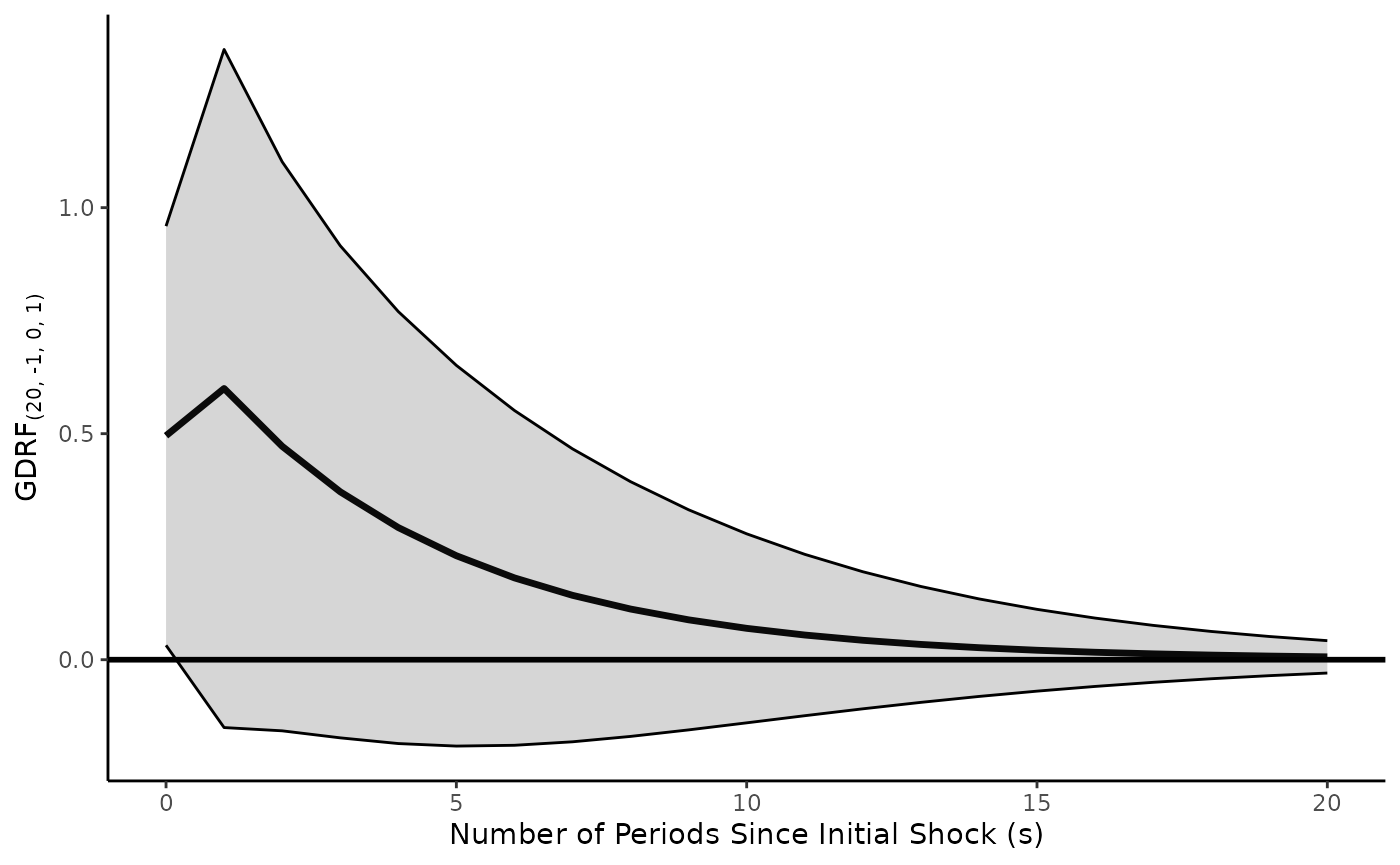
The same changes could be made to inferences.y (if
were modeled in differences). d.x should be entered as the
form of the independent variable, even if the user desires the effects
of a shock recovered in the differenced form (this should be handled by
inferences.x). The same is true of d.y.
GDRF.gecm.plot is extremely similar. Imagine the
following specified GECM model (with a first lag only of each
and
in levels)
# Fit a GECM(1, 1)
model.gecm <- lm(d_y ~ l_1_y + l_1_d_y + l_1_x + d_x + l_1_d_x, data = toy.ts.interaction.data)Since both the
and
variables appear in levels and differences, we need to differentiate
them. GDRF.gecm.plot does this by separating them into two
forms
-
x.vrbl: a named vector of the x variables (of the lower level of differencing, usually in levels d = 0) and corresponding lag orders in the GECM model -
y.vrbl: a named vector of the (lagged) y variables (of the lower level of differencing, usually in levels d = 0) and corresponding lag orders in the GECM model -
x.vrbl.d.x: the order of differencing of the x variable (of the lower level of differencing, usually in levels d = 0) in the GECM model -
y.vrbl.d.y: the order of differencing of the y variable (of the lower level of differencing, usually in levels d = 0) in the GECM model -
x.d.vrbl: a named vector of the x variables (of the higher level of differencing, usually first differences d = 1) and corresponding lag orders in the GECM model -
y.d.vrbl: a named vector of the y variables (of the higher level of differencing, usually first differences d = 1) and corresponding lag orders in the GECM model -
x.d.vrbl.d.x: the order of differencing of the x variable (of the higher level of differencing, usually first differences d = 1) in the GECM model -
y.d.vrbl.d.y: the order of differencing of the y variable (of the higher level of differencing, usually first differences d = 1) in the GECM model
The orders of differencing of y.vrbl and
y.d.vrbl (as well as x.vrbl and
x.d.vrbl) must be separated by only one order. From here,
all of the other arguments are the same. (Unlike in
GDRF.gecm.plot, inferences.x and
inferences.y must be in levels, given the dual nature of
the variables in the model.) For model.gecm, the syntax
would be
gecm.pulse <- GDRF.gecm.plot(model = model.gecm,
x.vrbl = c("l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
x.vrbl.d.x = 0,
y.vrbl.d.y = 0,
x.d.vrbl = c("d_x" = 0, "l_1_d_x" = 1),
y.d.vrbl = c("l_1_d_y" = 1),
x.d.vrbl.d.x = 1,
y.d.vrbl.d.y = 1,
shock.history = "pulse",
inferences.y = "levels",
inferences.x = "levels",
s.limit = 20,
return.plot = TRUE,
return.formulae = TRUE)Examining the formulae show that the conversion from GECM
coefficients to ADL coefficients is automatic. As before, if we wanted a
different shock history, we would just adjust shock.history
to apply a different shock history to
in levels.
User-friendly conditional effects:
interact.adl.plot
(Warner, Vande Kamp, and Jordan 2026) advocate for a general model that allows for conditional dynamic relationships to unfold unrestricted over time. They demonstrate the superiority of this approach to a restricted model. It requires the estimation of a contmeporaneous interaction, cross-period interactions (i.e. and and vice versa), and lagged interactions (i.e. and ).
They provide formulae for calculating effects, but no implementation of these formulae in software. Moreover, they do not explicitly recognize the conditional role of time itself (, in our parlance) in moderating calculated interactive effects (see Jordan, Vande Kamp, and Rajan (2022) and Brambor, Clark, and Golder (BramborClarkGolder2006?)).
We resolve these deficiencies through interact.adl.plot.
Many of the arguments are familiar
-
model: a (well specified, etc.) ADL model, likely following the general recommendation of (Warner, Vande Kamp, and Jordan 2026) -
x.vrbl: a named vector of the “main” variables and corresponding lag orders in the ADL model -
z.vrbl: a named vector of the “moderating” variables and corresponding lag orders in the ADL model -
y.vrbl: a named vector of the variable and its lag orders (if a lagged dependent variable is in the model) -
x.z.vrbl: a named vector with the interaction variables and corresponding lag orders in the ADL model
We pause to note something extremely important: x.z.vrbl
should be constructed such that the lag orders reflect the lag order
that pertains to the “main”
variable. For instance, x_l_1_z (contemporaneous
times lagged
)
would be 0 and z_l_1_x (lagged
times contemporaneous
)
would be 1.
Four arguments pertain to how the interactive effect should be visualized (following Jordan, Vande Kamp, and Rajan (2022))
-
effect.type: whether impulse or cumulative effects should be calculated.impulsegenerates impulse effects, or short-run/instantaneous effects specific to each period.cumulativegenerates the accumulated, or long-run/cumulative effects up to each period (including the long-run multiplier) -
plot.type: whether to feature marginal effects at discrete values of / as lines, or across a range of values through a heatmap -
line.options: if drawing lines, whether the moderator should be values of or -
heatmap.options: if drawing a heatmap, whether all marginal effects should be shown or just statistically significant ones
Users are encourgaed to experiment with many types of visualization: they all simply illustrate the underlying conditionality in the model. Aesthetics are generally presented with nice defaults, but options include
-
line.colors: defaults to colorsafe Okabe-Ito colors, but any vector of colors (matching the number of lines) can be used (including a black and white graphic withbw) -
heatmap.colors: defaults to Blue-Red, but anyhcl.palis possible. We also create one for black and white graphics withGrays -
z.label.rounding: the number of digits to round to in a legend, if values are not discrete -
z.vrbl.label: the label to use for the variable in plots
A final set of controls involves the values of to calculate and plot across
-
z.vals: ifplot.type = lines, these are treated as discrete levels of . Ifplot.type = heatmap, these are treated as a lower and upper level of a range of values of -
s.vals: ofline.options = s.lines, the values for the time since the shock. The default is 0 (short-run) and theLRM
All of these arguments have reasonable defaults. The arguments
dM.level, s.limit, se.type,
return.data, return.plot, and
return.formulae are also available.
For a final time, let’s estimate a general model (just assuming it is well behaved)
data(toy.ts.interaction.data)
# Fit an ADL(1, 1)
interact.model <- lm(y ~ l_1_y + x + l_1_x + z + l_1_z +
x_z + z_l_1_x +
x_l_1_z + l_1_x_l_1_z, data = toy.ts.interaction.data)Let’s first illustrate a line type, where the moderation is shown a
different values of
over time. The shock history is a simple
effect.type = "impulse"
interact.adl.plot(model = model.toydata, x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
z.vrbl = c("z" = 0, "l_1_z" = 1),
x.z.vrbl = c("x_z" = 0, "z_l_1_x" = 1, "x_l_1_z" = 0, "l_1_x_l_1_z" = 1),
z.vals = -1:1,
effect.type = "impulse", plot.type = "lines", line.options = "z.lines",
s.limit = 20)If we wanted to moderate by instead
interact.adl.plot(model = model.toydata, x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
z.vrbl = c("z" = 0, "l_1_z" = 1),
x.z.vrbl = c("x_z" = 0, "z_l_1_x" = 1, "x_l_1_z" = 0, "l_1_x_l_1_z" = 1),
z.vals = -1:1,
s.vals = c(0, 5),
effect.type = "impulse", plot.type = "lines", line.options = "s.lines",
s.limit = 20)We observe two lines: the instantaneous effect at
and the period-specific effect at
.
If we wanted to see these as a step (cumulative), rather than a pulse,
we would just change the effect.type.
interact.adl.plot(model = model.toydata, x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
z.vrbl = c("z" = 0, "l_1_z" = 1),
x.z.vrbl = c("x_z" = 0, "z_l_1_x" = 1, "x_l_1_z" = 0, "l_1_x_l_1_z" = 1),
z.vals = -1:1,
s.vals = c(0, 5),
effect.type = "step", plot.type = "lines", line.options = "s.lines",
s.limit = 20)If we wanted to see the period-specific effects of
across the full range of
,
since it is continuous, the heatmap makes the most sense. Notice we omit
z.vals this time to show that the function establishes
reasonable defaults.
interact.adl.plot(model = model.toydata, x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
z.vrbl = c("z" = 0, "l_1_z" = 1),
x.z.vrbl = c("x_z" = 0, "z_l_1_x" = 1, "x_l_1_z" = 0, "l_1_x_l_1_z" = 1),
effect.type = "pulse", plot.type = "heatmap", heatmap.options = "all",
s.limit = 20)If we want to ignore statistically insignificant effects, we can
change the heatmap.options to be
significant
interact.adl.plot(model = model.toydata, x.vrbl = c("x" = 0, "l_1_x" = 1),
y.vrbl = c("l_1_y" = 1),
z.vrbl = c("z" = 0, "l_1_z" = 1),
x.z.vrbl = c("x_z" = 0, "z_l_1_x" = 1, "x_l_1_z" = 0, "l_1_x_l_1_z" = 1),
effect.type = "pulse", plot.type = "heatmap", heatmap.options = "significant",
s.limit = 20)Concluding thoughts
A word of caution: tseffects is very naive to your
model. This is true in three ways. First, it relies on the user to
specify the lag structure correctly in both the underlying
lm model as well as the corresponding plot you are
producing. Including a term in the model, but not passing it to the
plotting function (i.e. to GDRF.adl.plot through
x.vrbl) will cause the calculation of the effects to be
inaccurate. interact.adl.plot is completely uninformed
about the underlying model: if there are interactive terms included in
the model but not included in interact.adl.plot, the effect
estimates will be incorrect. If a lagged variable is ommitted, the
effect estimates will be incorrect. It is incumbent on the user to
ensure that the model is well specified and that the specification is
fully reflected in the interpretation function used.
Second, and to reiterate, it makes no check that your model is well specified. The best starting place for a calculation of effects is always a well-specified model; users should complete this before obtaining inferences. See the citations at the beginning of the vignette for places to start.
Third, it does not pass judgement on the shock history you are
applying. Stationary (d.x = 0) variables cannot trend by
definition, but specifying shock.history = 1 in the
function would apply a linear trend shock history anyway. This is not a
good idea and is inconsistent with the underlying independent variable.
However, shock histories are hypothetical, and we are loathe to limit
the ability of a user to specify a counterfactual, consistent or not. We
leave it in the user’s hands to determine if their shock is sensible or
not.
Despite these words of caution, tseffects hopefully
simplifies the job of the time series analyst in obtaining a variety of
effects.